Compare AI models side-by-side. One prompt, up to ten answers.
Backplain runs the same prompt through up to 10 frontier models — GPT-5.x, Claude Sonnet 4.5, Gemini 2.5, Llama 4, Mistral, Grok — simultaneously. Where they agree, the answer is trustworthy. Where they disagree, that's the signal.
Because no single model is right about everything.
Every frontier lab publishes benchmarks. None of them describe how a model performs on your contract, your protocol, your filing. The only reliable way to know which model to trust for a specific question is to ask several of them the same question at the same time — and read the answers next to each other.
That is what Backplain does. Not a leaderboard. Not a benchmark. The actual prompts you actually run, through the actual frontier models, in one view.
47 frontier models. Compare any of them.
| Model | Maker | Context | Modality | License / Host | Where it wins |
|---|---|---|---|---|---|
| GPT-5.5 | OpenAI | 400K | Text + image + audio + video | Closed API | General reasoning, agent tool use |
| GPT-5 | OpenAI | 400K | Text + image + audio | Closed API | Decisive reasoning, code generation |
| o3 | OpenAI | 200K | Text | Closed API | Hard reasoning, math, science |
| GPT-4o mini | OpenAI | 128K | Text + image | Closed API | Fast, cheap, high-volume tasks |
| Claude Sonnet 4.5 | Anthropic | 1M | Text + image + PDF-native | Closed API | Long-doc reasoning, refactor, careful writing |
| Claude Opus 4 | Anthropic | 200K | Text + image | Closed API | Deepest reasoning, nuanced analysis |
| Claude Haiku 3.5 | Anthropic | 200K | Text + image | Closed API | Fast, cheap Claude tier |
| Gemini 2.5 Pro | 2M | Text + image + audio + video (native) | Closed API | Very long context, multimodal, Search-grounded | |
| Gemini 2.5 Flash | 1M | Text + image + video | Closed API | High-throughput multimodal at low cost | |
| Llama 4 Maverick | Meta | 1M | Text + image | Open weights · self-host / hosted | Open-weight breadth, cheapest at scale |
| Llama 4 Scout | Meta | 10M | Text | Open weights · self-host / hosted | Extreme context, on-prem-capable |
| Mistral Large 2 | Mistral | 128K | Text | Open weights · EU-hosted | Efficient reasoning, EU data residency |
| Codestral 25.01 | Mistral | 256K | Text (code) | Open weights · EU-hosted | Specialized code — 80+ languages |
| Pixtral Large | Mistral | 128K | Text + image | Open weights · EU-hosted | EU-hosted vision |
| Grok 3 | xAI | 128K | Text + image | Closed API | Real-time knowledge, less-filtered answers |
| Sonar Pro | Perplexity | 200K | Text (web-grounded) | Closed API | Cited web research |
| Nova Pro | Amazon | 300K | Text + image + video | Closed API · AWS-native | AWS-native workloads |
| Sovereign models | Backplain | Varies | Text + image | On our infrastructure | Air-gapped, sovereign, and regulated workloads |
Context = maximum prompt length. Modality = what each model can accept as input. Lineup refreshed continuously; deprecated models retired with notice. New frontier models added within days of release.
The matchups people ask about.
The two most-used AI assistants in the world. GPT-5 against Gemini 2.5 Pro on reasoning, long context, and multimodal.
GPT-5.x against Claude Sonnet 4.5 and Opus 4 — the two most-asked-about frontier models, side by side.
Head-to-head on reasoning, code, long-context, and cost — with the same prompt run through both.
Google's Gemini 2.5 Pro against OpenAI's GPT-5.x on research, multimodal, and enterprise fit.
The two leading open-weight frontier models — where they win, where they don't.
Claude Sonnet 4.5, GPT-5, Codestral, Gemini, Llama — ranked and compared for code generation and refactor work.
| Leaderboard sites | OpenRouter / aggregators | Backplain | |
|---|---|---|---|
| Run your own prompt | No — benchmark scores only | Yes | Yes |
| Side-by-side output on one screen | No | Limited | Up to 10 models, streaming |
| Files, PDFs, images in the prompt | No | Varies | Yes — same file to every model |
| PII / PHI redaction before the model sees it | N/A | No | Yes — patent-pending AI Firewall |
| Prompt-level audit log | No | No | Yes, from seat one |
| Team workspace with Model Groups | No | No | Yes |
| Price | Free (informational only) | Metered by tokens | $129/seat/mo flat |
1. Write one prompt
Ask your real question — a contract clause, a research query, a code review, a differential diagnosis. Attach files if you need to.
2. Pick your models
Select any 2–10 models from the 47 available. Save the selection as a Model Group so your team defaults to the same lineup.
3. Read the disagreement
Responses stream side by side. Where they agree, you're done. Where they disagree, you know exactly where to look.
Compare AI models for your domain.
Contract review, discovery, memos, research — which frontier model wins for which legal task.
Clinical summarization, protocol review, prior auth — HIPAA-safe multi-model comparison.
10-K analysis, diligence, memo drafting, IC prep — with MNPI on the right side of the firewall.
Sovereign, on-prem, and dedicated deployment options for ITAR, CUI, and air-gapped work.
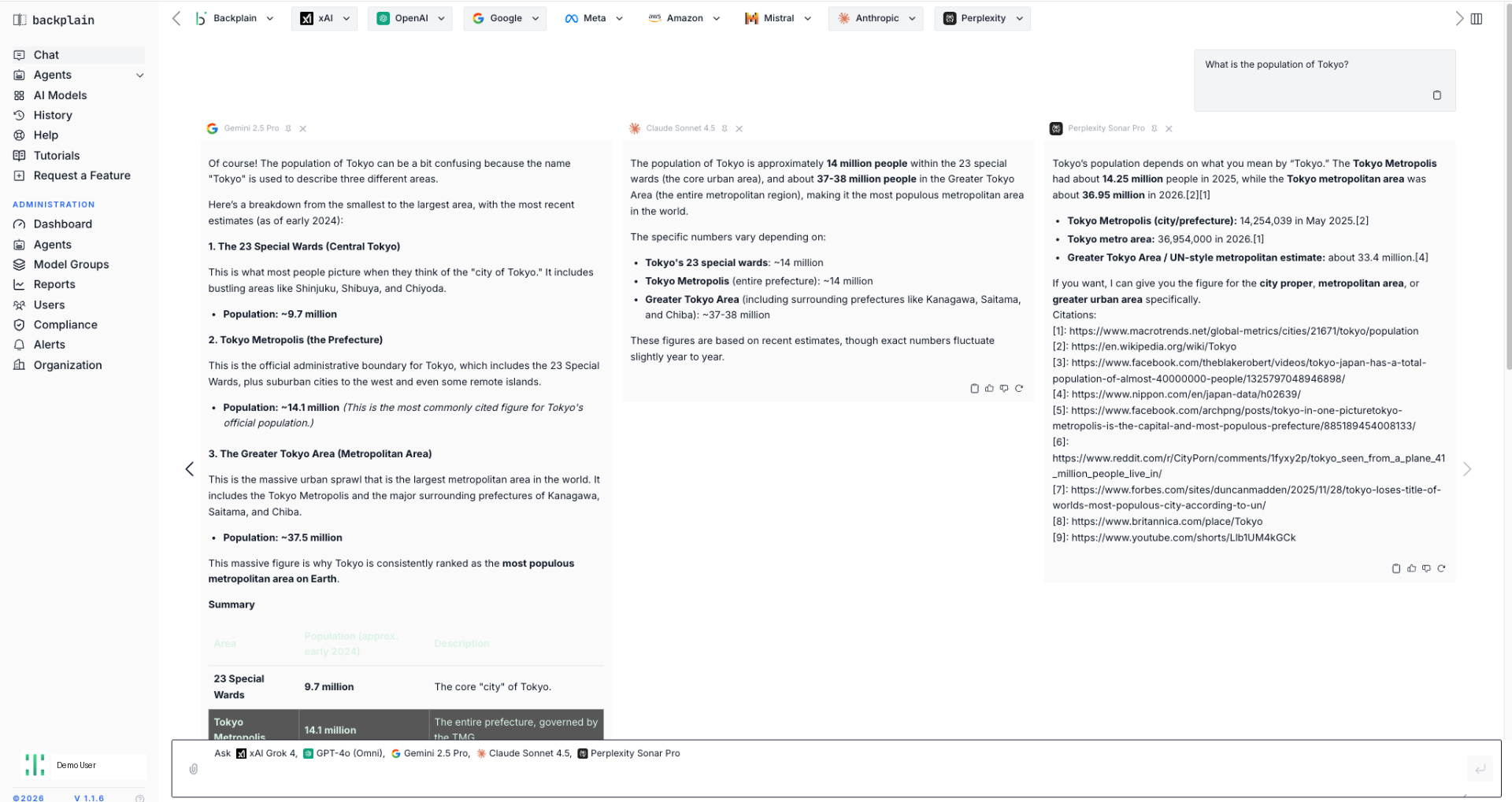
Tokyo Test — 3 free prompts, no signup
Run three real multi-model prompts against our full lineup without registering. See the disagreement live.
Run the Tokyo Test →Guided demo — full workspace, 47 models
Every model, every feature. Bring your own contracts and protocols; compare on your actual work with a Backplain engineer on the call.
Learn more →Not ready to try it? Get the Model Comparison Guide.
A one-page cheat sheet: which of the 47 frontier models to trust for which task. Sent to your inbox.
We'll only use your email to send the guide and occasional Backplain updates. Unsubscribe anytime.
Stop guessing which model to trust. Compare them.
One prompt. Up to ten frontier models. The disagreement is the signal.